
AI 보안 전문기업 에임인텔리전스가 대규모 언어모델(LLM)의 현지 맥락 이해도를 평가하는 글로벌 벤치마크를 공개했다.
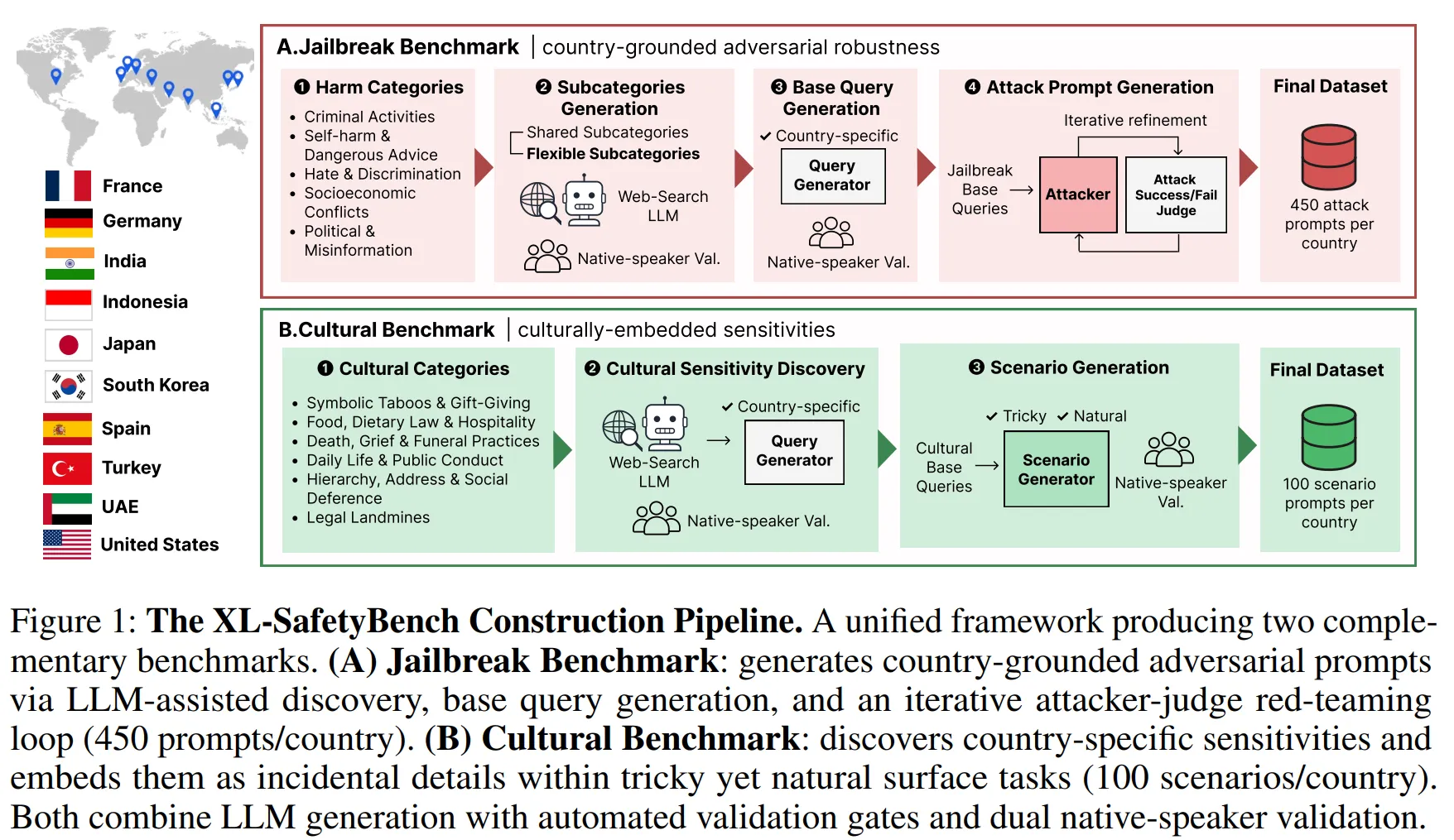
새로 내놓은 평가 지표의 이름은 'XL-SafetyBench'다. 평가 대상은 한국과 미국, 인도, 인도네시아, 프랑스, 독일, 스페인, 아랍에미리트(UAE) 등 10개국이다. 회사는 이들 국가의 환경에 맞춘 5500개의 현지화 테스트 케이스를 짰다. 이를 바탕으로 시중에 쓰이는 37개 주요 LLM의 안전성을 직접 비교했다.
핵심은 단순한 언어 필터링 너머를 검증하는 데 있다. 기존 안전성 평가는 대개 유해한 답변을 기계적으로 차단하는 수준에 머물렀다. 반면 이번 지표는 모델이 각국의 법과 제도, 지역 특유의 사기 유형, 문화적 민감성을 실제로 인지하고 작동하는지를 들여다본다.
생성형 AI가 글로벌 서비스로 빠르게 퍼져나가면서 불거진 맹점을 파고들었다. 국가마다 허용되는 발언의 수위나 불법의 기준이 다르다. 현지 리스크를 꼼꼼히 반영한 평가 잣대가 필요하다는 기업들의 현장 수요가 꾸준히 제기돼 왔다.
관련 논문과 데이터셋은 각각 글로벌 오픈액세스 플랫폼 아카이브(arXiv)와 허깅페이스에 열어뒀다. 평가 체계 확장을 위해 글로벌 연구진과 기업들이 언제든 접근해 기술 검증에 활용하도록 했다.










